Dodano: poniedziałek, 17 październik 2011r.

Unix i Linux. Przewodnik administratora systemów. Wydanie IV
Evi Nemeth, Garth Snyder, Trent R. Hein, Ben Whaley
Cena: 199.00 zł
Druga część rozdziału nr 7 książki:
Unix i Linux. Przewodnik administratora systemów. Wydanie IV
Plik /etc/passwd zawiera listę użytkowników rozpoznawanych przez system. Może on zostać rozszerzony lub zastąpiony przez usługę katalogową, stanowi więc kompletne i autorytatywne rozwiązanie tylko w samodzielnych systemach.
Podczas logowania system odwołuje się do pliku /etc/passwd, aby określić m.in. identyfikator użytkownika (UID) i jego katalog domowy. Każdy wiersz w tym pliku reprezentuje jednego użytkownika i zawiera siedem pól rozdzielonych dwukropkami. Oto te pola:
Przykładowo poniższe wiersze są prawidłowymi wpisami pliku /etc/passwd:
root:x:0:0:The System,,x6096,:/:/bin/sh
jl:!:100:0:Jim Lane,ECOT8-3,,:/staff/jl:/bin/sh
dotty:x:101:20::/home/dotty:/bin/tcsh
Zaszyfrowane hasła umieszczane były w drugim polu, ale nie jest to już bezpieczne rozwiązanie; przy wykorzystaniu szybkiego sprzętu ich złamanie (odszyfrowanie) jest kwestią minut. Obecnie wszystkie wersje systemów Unix i Linux ukrywają zaszyfrowane hasła i umieszczają je w oddzielnym pliku, który nie jest przeznaczony do odczytu dla innych. W systemach Linux, Solaris i HP-UX plik passwd w polu przeznaczonym na zaszyfrowane hasło zawiera znak x, a w systemie AIX jest to ! lub * (w przypadku AIX znak * jest symbolem zastępczym, który wyłącza konto).
W rzeczywistości zaszyfrowane hasło w systemach Linux, Solaris i HP-UX przechowywane jest w pliku /etc/shadow, a w systemie AIX w pliku /etc/security/passwd. Mają one różne formaty.
Jeśli konta użytkowników są współdzielone za pośrednictwem usługi katalogowej, np. NIS lub LDAP, w pliku passwd mogą znajdować się specjalne wpisy rozpoczynające się znakiem + lub –. Wpisy te informują system o tym, w jaki sposób dane usługi katalogowej mają być zintegrowane z zawartością pliku /etc/passwd. Sposób integracji można również ustawić w pliku /etc/nsswitch.conf (lub /etc/nscontrol.conf w systemie AIX).
Więcej informacji na temat pliku nsswitch.conf można znaleźć na stronie 912.
W następnych punkach omówimy szczegółowo plik /etc/passwd.
Nazwy użytkowników muszą być unikatowe i — w zależności od systemu operacyjnego — muszą przestrzegać ograniczeń dotyczących długości i zestawu znaków. W tabeli 7.1 przedstawione zostały zasady obowiązujące w naszych przykładowych systemach. Nazwy użytkowników nie mogą nigdy zawierać dwukropków ani znaków nowego wiersza, ponieważ znaki te są używane odpowiednio jako separatory pól i separatory wpisów. Jeśli korzystasz z NIS lub NIS+, nazwy użytkowników mogą zawierać maksymalnie osiem znaków, niezależnie od stosowanego systemu operacyjnego.
Więcej informacji na temat NIS można znaleźć na stronie 908.
Pierwotnie systemy Unix dopuszczały stosowanie wyłącznie znaków alfanumerycznych i ograniczały długość nazwy użytkownika do ośmiu znaków. Każdy system ma nieco inne reguły, dlatego musisz przyjąć najbardziej restrykcyjne ograniczenia, aby zapobiec ewentualnym konfliktom. Taki konserwatyzm zagwarantuje, że użytkownicy będą mogli posługiwać się tą samą nazwą użytkownika na każdym komputerze. Najbardziej uniwersalnym rozwiązaniem jest stosowanie nazw składających się z ośmiu (lub mniej) znaków i zawierających wyłącznie małe litery, cyfry i znaki podkreślenia.
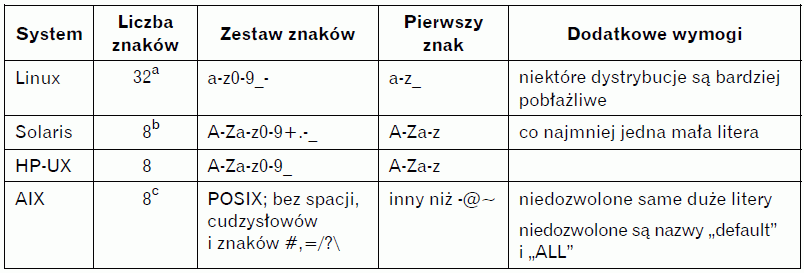
Tabela 7.1. Reguły tworzenia nazw użytkowników
a Choć Linux dopuszcza 32 znaki, tradycyjne programy (np. top lub rsh) oczekują 8 lub mniej znaków.
b To ograniczenie zostało zwiększone.
c W systemie AIX w wersji 5.3 lub wyższej można to zmienić, patrz następna strona.
W nazwach użytkowników uwzględnia się wielkość znaków. Dokument RFC 822 nakazuje jednak, aby w adresach e-mail wielkość znaków była ignorowana. Nic nam nie wiadomo o jakichkolwiek problemach związanych z łączeniem dużych znaków z małymi w nazwach użytkowników, ale tradycyjnie stosuje się nazwy zawierające małe znaki, poza tym są one łatwiejsze do wpisywania. Jeśli nazwy użytkowników jan i Jan przypisane będą różnym osobom, mogą wystąpić problemy związane z pocztą.
Nazwy użytkowników powinny być łatwe do zapamiętania, dlatego przypadkowa sekwencja znaków nie jest dobrą nazwą. Unikaj stosowania przezwisk nawet wtedy, kiedy w Twojej organizacji panują nieformalne stosunki. Nazwy w rodzaju DarkLord lub FajnaLaska pasują bardziej do @hotmail.com. Jeśli Twoi użytkownicy nie mają żadnego szacunku dla siebie, weź pod uwagę choćby ogólną wiarygodność Twojej organizacji.
Ponieważ nazwy użytkowników są często używane w adresach e-mail, warto ustalić standardowy sposób ich tworzenia. Użytkownicy powinni samodzielnie odgadnąć nazwy pozostałych użytkowników. Rozsądny schemat nazewniczy musi raczej zakładać użycie imion, nazwisk, inicjałów lub kombinacji tych elementów.
Bez względu na przyjęty schemat wyboru nazw użytkowników i tak w końcu dojdzie do sytuacji, w której wystąpią zduplikowane lub zbyt długie nazwy, dlatego czasami trzeba robić wyjątki. Określ standardowy sposób postępowania w przypadku konfliktów, np. dodanie numeru na końcu nazwy. Przy zbyt długich nazwach możesz wykorzystać funkcję nazw zastępczych swojego systemu pocztowego, aby utożsamić dwie wersje nazwy, co przynajmniej rozwiązuje problem z pocztą.
W dużych organizacjach często stosuje się adresy e-mail zawierające pełne imię i nazwisko (np. Jan.Kowalski@mojawitryna.com), dzięki czemu właściwe nazwy użytkowników pozostaną nieznane dla osób postronnych. To dobry pomysł, ale nie zwalnia od obowiązku stosowania przedstawionych wyżej wskazówek. Najlepiej, aby nazwy użytkowników miały ścisły oraz przewidywalny związek z ich faktycznymi imionami i nazwiskami, choćby dla samego ułatwienia administrowania, jeśli nie ma innych powodów.
Nazwy użytkowników powinny być unikatowe z dwóch powodów. Po pierwsze, użytkownik powinien na każdym komputerze logować się za pomocą tej samej nazwy. Ta zasada służy głównie dla wygody zarówno Twojej, jak i użytkownika.
Po drugie, określona nazwa użytkownika powinna zawsze odnosić się do tej samej osoby. Niektóre polecenia (np. ssh) mogą być skonfigurowane w taki sposób, że zdalni użytkownicy będą weryfikowani na podstawie ich nazw. Jeśli scott@boulder.colorado.edu i scott@refuge.colorado.edu to dwie różne osoby, przy niewłaściwie skonfigurowanych kontach jeden użytkownik scott mógłby zalogować się na konto drugiego użytkownika o tej samej nazwie bez podawania hasła.
Z doświadczenia wynika, że zduplikowane nazwy prowadzą do pomyłek w dostarczaniu poczty. System pocztowy może doskonale odróżniać obu użytkowników o nazwie scott, ale często inni użytkownicy będą wysyłali pocztę pod zły adres.
Jeśli w Twojej organizacji istnieje globalny plik nazw zastępczych (aliasów), nowe nazwy użytkowników nie mogą się pokrywać z żadną z nazw określonych w tym pliku. W przeciwnym razie poczta zostanie dostarczona użytkownikowi, do którego należy dana nazwa zastępcza, a nie nowemu użytkownikowi.
Więcej informacji na temat stosowania nazw zastępczych w adresach pocztowych można znaleźć na stronie 935.
AIX: W systemie AIX można zmienić maksymalną długość nazwy użytkownika za pomocą polecenia chdev. Odpowiednie urządzenie nosi nazwę sys0. Polecenie lsattr -D -l sys0 wyświetli listę domyślnych atrybutów urządzenia. Jednym z nich jest atrybut max_logname, który odpowiada za maksymalną długość nazwy użytkownika. Poniższe polecenie wyświetli tylko ten konkretny atrybut:
aix$ lsattr -El sys0 -a max_logname
max_logname 9 Maximum login name length at boot time True
Aby zmienić to ograniczenie, użyj poniższego polecenia. Zmiana zostanie wprowadzona przy następnym uruchomieniu systemu.
(Na początku nam się to nie udawało, ponieważ korzystaliśmy z sudo (patrz strona 186), a zmienne środowiskowe ustawione przez polecenie sudo zazwyczaj są inne niż wtedy, gdy najpierw wydajemy polecenie sudo su -, a dopiero potem właściwe polecenie. Polecenie chdev zwraca na to uwagę. Nowe wersje polecenia sudo (1.70 lub wersje późniejsze) mają opcję –i, którą można zastosować w takich sytuacjach.)
aix$ sudo su -
aix# chdev -l sys0 -a max_logname=16
System podaje, że domyślna długość nazwy to dziewięć znaków, ale specyfikacja długości w systemie AIX to rozmiar bufora, a w nim mieści się jeszcze znak null, który przerywa łańcuch. Dlatego też faktyczny domyślny limit to tylko osiem znaków, a nasze polecenie chdev ustawia limit na piętnaście znaków.
AIX obsługuje znaki wielobajtowe (np. dla języków azjatyckich), ale nie zaleca się ich używania. Sugerowanym rozwiązaniem jest stosowanie znaków dopuszczalnych w nazwach plików zgodnie ze standardem POSIX.
Nowoczesne systemy nie przechowują hasła w pliku /etc/passwd, a przy pierwszym logowaniu proszą użytkownika o podanie prawdziwego hasła. Ponadto, oprócz standardowego algorytmu crypt systemu Unix, obsługują również kilka innych metod szyfrowania. Zaszyfrowane hasło jest oznaczane w celu identyfikacji sposobu szyfrowania użytego do jego wygenerowania. Nasze przykładowe systemy obsługują wiele różnych algorytmów szyfrowania: tradycyjny crypt (oparty na DES), MD5, Blowfish oraz iteratywną wersję MD5 zapożyczoną z projektu serwera WWW Apache.
Kolejną ważną kwestią jest długość hasła często określana przez algorytm wykorzystany do szyfrowania. W tabeli 7.2 przedstawione zostały maksymalne i minimalne długości haseł oraz algorytmy szyfrowania dostępne w naszych przykładowych systemach. Niektóre systemy umożliwiają wpisanie dowolnie długiego hasła, ale „po cichu” przycinają je zgodnie z limitem podanym w tabeli.

Tabela 7.2. Algorytmy szyfrowania i ograniczenia długości hasła
a W systemach SUSE i openSUSE domyślnym algorytmem jest Blowfish; większość pozostałych używa MD5.
b Maksymalna długość zależy od wybranego algorytmu.
c Administrator (root) może ustawić nazwę użytkownika o dowolnej długości.
d Ten plik zawiera bardzo dużo konstrukcji #ifdef, dlatego jest dość trudny do odczytania i zrozumienia.
Jeśli pominiesz systemowe narzędzia do dodawania użytkowników i zdecydujesz się utworzyć nowe konto przez ręczną edycję pliku /etc/passwd (oczywiście, za pomocą vipw; patrz strona 274), w polu przeznaczonym na zaszyfrowane hasło wpisz znak gwiazdki lub x. Zapobiegnie to możliwości nieautoryzowanego użycia konta przed ustawieniem właściwego hasła przez Ciebie lub użytkownika. Nigdy, w żadnym przypadku nie pozostawiaj tego pola pustego, bo możesz doprowadzić do ogromnej luki w bezpieczeństwie systemu, ponieważ wtedy dostęp do tego konta nie wymaga podania żadnego hasła.
Algorytm MD5 pod względem kryptograficznym jest nieco lepszy niż poprzedni standard DES używany przez crypt, poza tym mechanizm MD5 umożliwia stosowanie haseł o dowolnej długości. Dłuższe hasła są bezpieczniejsze — pod warunkiem, że z nich korzystasz. W algorytmie MD5 odkryto pewne niedoskonałości, ale na standard DES udało się przeprowadzić skuteczne ataki typu brute-force. Algorytmy SHA256 i Blowfish to prawdziwi siłacze w dziedzinie szyfrowania. Na stronie 1111 podane zostały wskazówki dotyczące wyboru haseł.
Zaszyfrowane hasła mają stałą długość (trzydzieści cztery znaki dla MD5, trzynaście dla DES), bez względu na długość niezaszyfrowanego hasła. Hasła są szyfrowane w połączeniu z wartościami losowymi (ang. salt), aby dane hasło mogło przyjmować wiele zaszyfrowanych form. Jeśli dwóch użytkowników wybierze to samo hasło, nie można będzie odkryć tego faktu przez porównanie zaszyfrowanych haseł. Hasła MD5 są łatwe do zauważenia, ponieważ zawsze rozpoczynają się od $1$ lub $md5$. ($1$ to oznaczenie algorytmu MD5 w BSD; Sun stosuje własny wariant MD5 i oznacza go $md5$.).
Hasła zaszyfrowane algorytmem Blowfish rozpoczynają się od $2a$, a hasła SHA256 — od $5$.
SUSE: Dla nowych haseł system SUSE stosuje domyślnie algorytm Blowfish, co jest bardzo rozsądnym rozwiązaniem. Szukaj prefiksu $2a$.
OpenSolaris: Obecnie w OpenSolaris domyślnym algorytmem jest SHA256 (prefiks $5$), choć wcześniejsze wersje używały domyślnie MD5.
Numer UID identyfikuje użytkownika w systemie. Nazwy użytkowników służą tylko ich wygodzie, bo oprogramowanie i system plików posługują się wewnętrznie numerami UID. Identyfikatory UID to zwykle 32-bitowe liczby całkowite bez znaku.
Użytkownik root z definicji ma identyfikator UID o numerze 0. Większość systemów definiuje również pseudoużytkowników, takich jak bin i daemon, którzy są właścicielami plików konfiguracyjnych. Tradycyjnie tacy sztuczni użytkownicy umieszczani są na początku pliku /etc/passwd i mają przyznane niskie numery UID oraz fałszywą powłokę (np. /bin/false), żeby nikt nie mógł się zalogować na ich konta. Aby pozostawić dużo miejsca dla takich pseudoużytkowników, których mógłbyś dodawać w przyszłości, zalecamy, aby identyfikatory UID prawdziwych użytkowników rozpoczynały się od numeru 500 lub wyższego (pożądany zakres dla nowych identyfikatorów można określić w plikach konfiguracyjnych dla polecenia useradd).
Opis konta root można znaleźć na stronie 176.
Inny specjalny identyfikator UID należy do użytkownika o nazwie nobody; ma on zwykle przypisaną wartość –1 lub –2, co odpowiada najwyższemu i drugiemu w kolejności identyfikatorowi spośród wszystkich możliwych numerów UID. Nazwa nobody używana jest wtedy, gdy na jednym z komputerów użytkownik root próbuje uzyskać przez NFS dostęp do plików innego komputera, który nie ufa temu pierwszemu.
Więcej informacji na temat konta nobody można znaleźć na stronie 862.
Posiadanie wielu kont o identyfikatorze UID równym 0 to zły pomysł. Możliwość logowania się z uprawnieniami administratora na różne powłoki lub przy użyciu różnych haseł może wydawać się udogodnieniem, jednak takie ustawienie powoduje tylko większe zagrożenie dla bezpieczeństwa i konieczność zabezpieczenia wielu kont. Jeśli użytkownicy muszą mieć więcej sposobów logowania się z uprawnieniami użytkownika root, lepiej będzie, jeśli skorzystają z programów typu sudo.
Unikaj powtórnego wykorzystywania numerów UID nawet wtedy, kiedy użytkownicy opuścili już organizację, a ich konta zostały usunięte. Dzięki podjęciu takich środków ostrożności unikniesz zamieszania w sytuacji, gdyby kiedyś zaszła konieczność odtworzenia plików z kopii zapasowej, gdzie użytkownicy są identyfikowani za pomocą numerów UID, a nie nazw.
Numery UID muszą być unikatowe w całej organizacji. Oznacza to, że określony numer UID powinien odnosić się do tej samej nazwy użytkownika i tej samej osoby na wszystkich komputerach, do korzystania z których jest uprawniona. Nieprzestrzeganie zasady niepowtarzalności numerów UID może zwiększyć zagrożenie dla bezpieczeństwa w takich systemach jak NFS, a także wprowadzać zamęt w sytuacji, gdy użytkownik zmieni swoją grupę roboczą.
Jeśli grupy komputerów są zarządzane przez różne osoby lub organizacje, utrzymanie unikatowych numerów UID może być trudne. Wiążą się z tym zarówno problemy natury technicznej, jak i politycznej. Najlepszym rozwiązaniem jest posiadanie centralnej bazy danych lub serwera katalogowego, który zawiera wpisy każdego użytkownika i wymusza niepowtarzalność. Prostszy schemat polega na przypisaniu określonego zakresu numerów UID każdej grupie w organizacji i pozwolenie jej na samodzielne zarządzanie swoimi zestawami. Takie rozwiązanie pozwala utrzymać odrębne przestrzenie numerów UID, ale nie rozwiązuje występujących równolegle problemów z unikatowymi nazwami użytkowników.
W zarządzaniu numerami UID i informacjami o kontach użytkowników dużą popularność zdobywa LDAP. Temat ten zostanie przedstawiony pobieżnie w tym rozdziale, od strony 290, a bardziej dokładnie omówimy go w rozdziale 19., „Współdzielenie plików systemowych”, od strony 899.
Podobnie jak UID, numery identyfikacyjne grup również są 32-bitowymi liczbami całkowitymi. GID o numerze 0 jest zarezerwowany dla grupy o nazwie root lub system. Tak samo jak w przypadku identyfikatorów UID, system dla własnych potrzeb administracyjnych korzysta z kilku predefiniowanych grup. Niestety, producenci nie zachowują tu żadnej konsekwencji. Przykładowo w systemach Red Hat i SUSE grupa bin ma identyfikator GID 1, a w systemach Ubuntu, Solaris, HP-UX i AIX grupa ta ma identyfikator o numerze 2.
W dawnych czasach, gdy moc obliczeniowa była droga, grupy służyły do celów rozliczeniowych. Chodziło o to, aby opłaty za wykorzystanie sekund czasu procesora, minut czasu zalogowania i kilobajtów zajętego miejsca na dysku zostały naliczone właściwemu wydziałowi. Obecnie grupy służą głównie do współdzielenia dostępu do plików.
Plik /etc/group definiuje grupy; korzysta przy tym z pola GID w pliku /etc/passwd, przyznając domyślny (lub „efektywny”) numer GID podczas logowania. Przy określaniu praw dostępu domyślny numer GID nie jest traktowany w jakiś szczególny sposób, ma znaczenie jedynie podczas tworzenia nowych plików i katalogów. Standardowo właścicielem nowych plików jest Twoja efektywna grupa, jeśli jednak chcesz udostępnić pliki innym użytkownikom w ramach jakiegoś projektu zespołowego, musisz pamiętać o tym, aby ręcznie zmienić właściciela grupowego tych plików.
Więcej informacji na temat ustawiania bitu setgid dla katalogów można znaleźć na stronie 233.
Aby ułatwić współpracę, możesz ustawić dla katalogu bit setgid (02000) lub zamontować system plików z opcją grpid. Oba te rozwiązania sprawią, że nowo tworzone pliki będą domyślnie należeć do tej samej grupy, co ich katalog nadrzędny.
Pole GECOS używane jest czasem do zapisywania informacji osobistych o każdym użytkowniku. Nie ma ściśle zdefiniowanej składni. Choć możesz tu przyjąć dowolną konwencję formatowania, polecenie finger interpretuje wpisy GECOS rozdzielone przecinkami w następującej kolejności:
Polecenie chfn umożliwia użytkownikom zmianę swoich informacji GECOS. (Wyjątkiem jest system Solaris, w którym nie ma polecenia chfn. Superużytkownik może zmienić informacje GECOS użytkownika za pomocą polecenia passwd –g).
Polecenie jest przydatne do zapisywania aktualnych informacji o użytkowniku, takich jak numer telefonu, ale może również zostać wykorzystane niewłaściwie. Użytkownik może np. wprowadzić tam niewłaściwe informacje lub treści obsceniczne. W niektórych systemach można ograniczyć pola, które mogą być modyfikowane za pomocą polecenia chfn; wiele ośrodków akademickich wyłącza je całkowicie. W większości systemów polecenie chfn może operować tylko na pliku /etc/passwd, jeśli więc do przechowywania informacji o użytkownikach wykorzystujesz LDAP lub inną usługę katalogową, chfn może w ogóle nie działać.
Więcej informacji na temat LDAP można znaleźć na stronie 899.
AIX: W systemie AIX polecenie chfn akceptuje opcję –R moduł, która wczytuje podany moduł w celu przeprowadzenia właściwej aktualizacji. Dostępne moduły znajdują się z katalogu /usr/lib/security, a jeden z nich może korzystać z LDAP.
Katalog domowy użytkownika jest podczas logowania katalogiem domyślnym. Musisz zdawać sobie sprawę z tego, że katalogi domowe zamontowane na sieciowym systemie plików mogą być niedostępne w przypadku problemów z serwerem lub siecią. Jeśli w czasie logowania katalog domowy użytkownika jest niedostępny, system wyświetli komunikat informujący o braku katalogu domowego i przeniesie użytkownika do katalogu /.
(Taki komunikat pojawi się tylko przy logowaniu na konsoli lub przez terminal, ale nie podczas logowania za pośrednictwem graficznych menadżerów logowania, takich jak xdm, gdm lub kdm. Wtedy nie tylko nie zobaczysz żadnego komunikatu, ale zostaniesz natychmiast wylogowany, ponieważ menadżer wyświetlania nie będzie miał możliwości zapisu do właściwego katalogu (np. ~/.gnome).)
System Linux nie pozwoli się zalogować, jeśli w pliku /etc/login.defs w wierszu DEFAULT_HOME wpisana będzie wartość no.
Powłoka logowania to zazwyczaj interpreter poleceń, np. powłoka Bourne’a lub C (/bin/sh lub /bin/csh), ale może to być dowolny program. W systemie Unix tradycyjnie powłoką domyślną jest sh, a w systemach Linux i Solaris jest nią bash (ang. „Bourne again” shell). (Gra słów; w języku angielskim brzmi to jak born again shell, czyli odrodzona powłoka — przyp. tłum.)
W systemie AIX powłoką domyślną jest ksh, powłoka Korna; tcsh to rozszerzona powłoka C z możliwością edycji poleceń. W systemach linuksowych sh i csh są w rzeczywistości po prostu dowiązaniami odpowiednio do powłok bash i tcsh.
Niektóre systemy umożliwiają użytkownikom zmianę swoich powłok za pomocą polecenia chsh, ale podobnie jak w przypadku chfn, polecenie to może nie działać, jeśli do zarządzania informacjami o użytkownikach wykorzystujesz LDAP lub inną usługę katalogową. Gdy używasz pliku /etc/passwd, administrator zawsze może zmienić powłokę użytkownika, edytując plik passwd za pomocą polecenia vipw.
Linux obsługuje polecenie chsh i ogranicza możliwość zmian do powłok wymienionych w pliku /etc/shells. SUSE również narzuca wybór z pliku /etc/shells, ale system Red Hat w przypadku wybrania powłoki spoza listy tylko ostrzega. Dodając nowe wpisy do pliku shells, pamiętaj o konieczności podania ścieżek bezwzględnych, ponieważ oczekują tego chsh i inne programy.
AIX: W systemie AIX użytkownik może zmienić swoją powłokę za pomocą polecenia chsh i wybrać inną z obszernej listy. Autorytatywna lista sprawdzonych powłok znajduje się w pliku /etc/security/login.cfg.(Do wprowadzania zmian w plikach z katalogu /etc/security użyj polecenia chsec, zamiast edytować je bezpośrednio.) Plik /etc/shells zawiera jedynie ich podzbiór i używany jest tylko przez demona FTP, in.ftpd. Wiele powłok z tej długiej listy to po prostu dowiązania twarde do pojedynczego pliku binarnego. Przykładowo sh, ksh, rksh, psh i tsh (zarówno w /bin, jak i w /usr/bin) są tym samym programem, który zmienia swoje zachowanie w zależności od tego, pod jaką nazwą został wywołany. Podobnie jak chfn, polecenie chsh przyjmuje opcję –R moduł w celu obsługi LDAP i innych systemów usług katalogowych.
Solaris: W systemie Solaris tylko superużytkownik może zmienić powłokę użytkownika (używając polecenia passwd -e). Plik /etc/shells (którego domyślnie nie ma, choć istnieje jego strona podręcznika systemowego) zawiera listę dozwolonych powłok.
cdn.
Pierwsza część dostępna jest pod adresem:
http://www.linuxportal.pl/artykuly/dodawanie-nowyc/.../-1-id98820
Wpisy z blogów/ TOP 30dni
